


Key takeaways
Data can be an incredibly valuable and useful tool in business, but its effectiveness is heavily dependent on its accuracy. It becomes even more complicated when the data involves massive piles of tables, spreadsheets, and databases scattered across various departments, product owners, apps, platforms, and devices, each with its own formats, values, and domains.
Using data in an organization can feel a little like trying to assemble furniture, but every piece of hardware you pull from the box uses a different measurement standard.
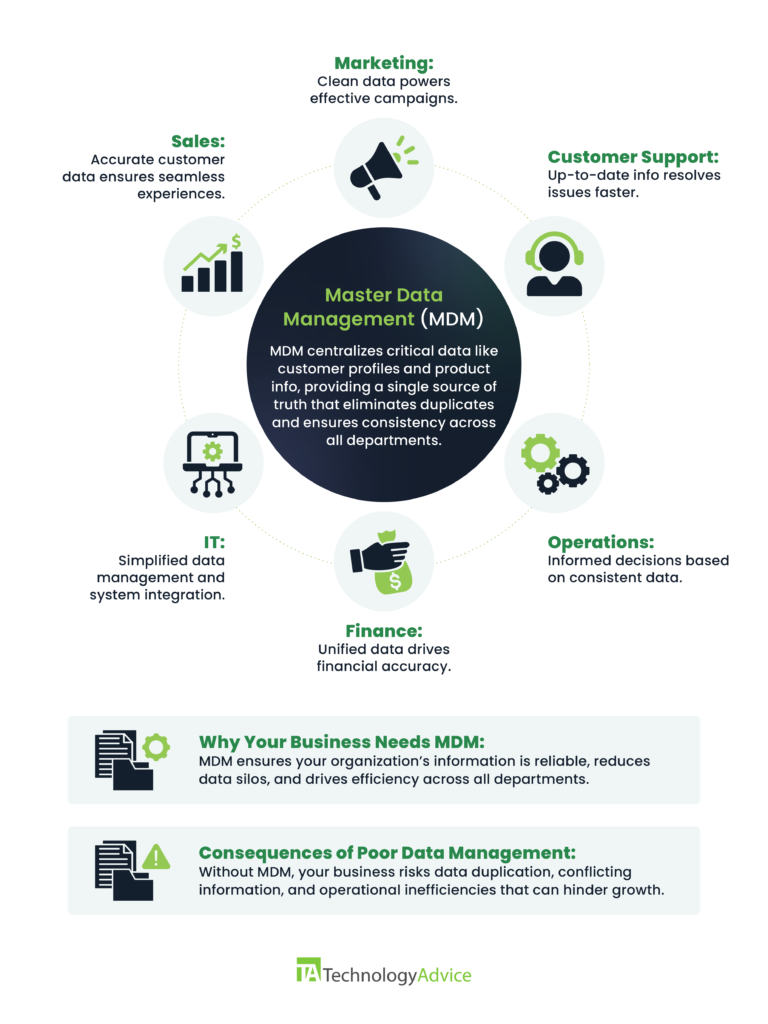
Having a common baseline, a core record that at the very least collects and standardizes the most important information, makes it easier to view, reference, and use. This “golden record” is called master data. The implementation, upkeep, and oversight of this master data is known as master data management (MDM).
Featured partners
What is master data management (MDM)?
Master data management is an aspect of data management and governance. It’s a practice that involves building a “single source of truth”—a core database of the critical information that’s used throughout an organization. Notably, different apps, platforms, and departments often use different parts of the information and frequently make changes to these values.
MDM establishes this master data then maintains it to ensure its accuracy and purity, even as the data continues to be used and manipulated at a virtually constant rate.
So, in short, master data is the “golden record,” the canon list of values that business processes reference during normal operations. Master data management encompasses the business’s entire approach to the implementation of master data and the continued maintenance thereof.
Why is master data management important?
Even our smartest software isn’t the best at “eyeballing” things. Computers can handle conditional statements (if/then, true/false, etc.), and they can handle randomness, percentages, and probability. What they’re less effective at is making contextual judgment calls.
This is the reason why AI-generated images struggle with human hands. They have a vague grasp of the many, many permutations hands might take in an image. But they don’t know when a given one might apply, and they certainly have no concept of why that might be. Without any idea of the way hands exist and move in physical space, the best they can do is guess or select “all of the above” (hence the superabundance of fingers).
All of this is to say that computers work a lot better for us when we can give them concrete, quantifiable information. A spreadsheet can handle a range of values, like 2–5; it’s not equipped to handle the speaker-specific fluctuations in meaning for words like “a few.” There’s no way to conditional format for people like Jeff, who means 3–8, or Melanie, who means either 4 or 5.
So, when your CRM tries to pull on a customer record but finds two similar entries for the name, it has no way to tell which one you want. It might serve up both to let you figure it out, but that reduces the time-saving effect that you were hoping for by using a digital record with a search function in the first place.
MDM is one of the primary methods of avoiding issues stemming from poor data integrity: duplicate entries, null values, collisions, formatting incompatibilities, errors introduced during the ETL/EDI process, and so on.
Because MDM prioritizes standardization and accuracy and defines both the data scrubbing parameters and the proper handling of conflicts or changes, it essentially gives the computer a flowchart to follow when things don’t add up. That’s a reductive description and doesn’t fully map onto MDM as an accurate metaphor, but in essence, that’s the how and why.
MDM sets the operating protocols for your data ecosystem, telling it, “This is what the data is supposed to look like,” “This is how to make it look like that,” and “This is what should be done when you find missing/incorrect/unexpected values.”
MDM in Action: An Airline Example
Airports handle more than aircraft, cargo, and passengers; they manage vast amounts of data. Each aircraft has numerous critical identifiers, starting with its name, which is mainly used by airline staff and maintenance crews. The flight number is universally important, needed by departure and arrival airports, flight crews, passengers, and other stakeholders. Flight numbers are transient, changing once the flight lands.
Passenger and luggage information is unique, as is staff data, though the latter is primarily relevant to the airline and specific flights. Beyond these, data includes terminals, gates, schedules, delays, and status updates. This complex system operates smoothly like a finely tuned clock, despite constant data changes and occasional disruptions, ensuring the right information reaches the right parties.
This efficiency is achieved through master data managed by an MDM strategy. For example, passenger identities are crucial not only for the airline but also for those picking them up or handling their luggage. However, not all departments need access to the same information—pilots, for instance, don’t require passenger names or seat details.
How to implement MDM: A step-by-step guide
Key objectives of your MDM implementation
When implementing MDM, there are at least three core objectives you’re seeking to satisfy in one way or another:
- Establishing a protocol for how data will be scrubbed and standardized for addition to the master data record.
- Establishing a protocol for how conflicts, modifications, and ongoing usage of the data will be reconciled between server and client (i.e., the master data and all the software on the periphery that references those values).
- Establishing a protocol for the tools and policies that will hopefully, over time, minimize the effort and investment needed to maintain the master data.
The decisions you make regarding architecture, applications/platforms, frameworks, operational processes, and training programs will help you find the right strategy for your organization to achieve critical goals like the three above.
How the pros get it done
Spend 15 minutes with a coder, SysAdmin, or data scientist, and you’ll quickly realize that “the right way” is a term as applicable in information systems as it is in heavy road traffic. There are definitely a number of easily identified ways to do things wrong, but nearly infinite possible ways that are viable and acceptable. Some may get you there faster than others or do so more economically, but that doesn’t mean they’re more correct.
Despite this, the “driver” you’re sitting next to will almost certainly believe that their speed of travel (metaphorically speaking, that is) is the most correct, and anyone traveling faster or slower than them is in error.
There is not a “right” answer. Just the most optimal answer for your use case. Keep that in mind for the next few paragraphs.
MDM comes primarily in two flavors, divided by what you’re doing with the data once it’s standardized.
- Analytical MDM: Seeks to ensure the accuracy and integrity of the data being piped into data warehouses.
- Operational MDM: Implemented to ensure that the whole team is referencing the same data, that the data is accurate, and that things don’t fall through the cracks because the computers get confused.
Operational MDM is what we’ve mostly been describing so far, as it’s far more likely you’re here with that in mind. In either case, though, the most common and most effective approaches are very similar in concept. Your MDM will involve applications, architecture, and administration:
- Scrubbing data is ultimately a question of finding the right tool for the job. In other words, you’re looking for software applications/platforms that can enable automation of the process. You do not want to be editing all those values manually, and you’re just as likely to introduce more errors if you do anyway.
- Arbitrating interactions between the master data and the client side (computer client, not business client) is primarily a concern that’s addressed at the architecture level. You can attempt to overlay something at the application layer, but that’s less effective, less efficient, and less economical (in the end, anyway).
- As for ongoing maintenance, a lot of this comes down to the tools you use (again), as well as how people are using said tools. Putting SOPs in place that do things like teach the standardized formats used in the master data will help a lot, but there will always be mistakes and errors, which is what the software tools are for.
Classical architecture
There’s a sliding scale of methodology here, depending on your situation.
One extreme end of this spectrum is “master data is ‘read-only’ everywhere, but the backend, and all the clients/source apps have to accept the changes as they’re made.” The other is “MDM is a silent observer, taking notes whenever a source app makes a change and updating the master record accordingly, but never interfering with the source app itself.”
Basically, the division is centralized data/decentralized data, or “trust the master” vs. “trust the source.” In many implementations, though, there will be some amount of hybridization here, allowing changes to be both “pushed” and “pulled” under certain circumstances.
The critical parts here are: There has to be a predetermined hierarchy regarding which record is treated as more accurate, there must be protocols for resolving conflicts and edge cases, and all of it has to be supported by the way the infrastructure is built at the foundational level.
Benefits and challenges of MDM
MDM benefits
Implementing MDM to achieve a single source of truth leads to a number of objectively positive outcomes, the majority falling into one of two categories:
- Smoother operations through improved data accuracy: Master data serves as a correctional reference. It helps avoid duplicates, incorrect entries, and missing data values and helps resolve conflicts when they do occur. For example, master data can ensure that a duplicate customer profile isn’t generated by accident, that a product isn’t shipped to an incorrect address when the correct one is already on file, and can provide missing info from a separate source app when another one needs it but didn’t collect it.
- Better GRC through effective data governance: Some organizations have to contend with more regulatory concerns than others, but at this point, how data is handled is an issue relevant to basically every business to one degree or another. One of the biggest issues in data governance is visibility, i.e., knowing what data you have, where it’s being stored, where it’s being used, and who has access privileges. MDM aids in improving visibility and oversight so that sensitive data can be more appropriately controlled and protected.
MDM challenges and drawbacks
There’s a lot to like about master data, but that troublesome management part might present some hurdles. Here are a few:
- People are the toughest computers to troubleshoot: As is so frequently the case, it’s the “wetware” that creates the biggest issues for those working with the system infrastructure. Achieving consensus on data standards, eliciting buy-in from stakeholders, and even just securing the necessary budget for needed changes are all examples of chokepoints where MDM efforts can come to a screeching halt.
- Critical mass: Because so much of MDM is addressed at the architectural level, it’s not a five-minute project. It doesn’t take a very big tech stack before implementing MDM becomes a major investment, and smaller organizations may not have the size or complexity to fully realize the benefits anyway. This goes both ways, though, as enterprise-level implementation has to contend with much bigger and more convoluted systems, meaning it’s even more expensive despite being a more justifiable expense.
- Resources, load, and overclocking: Any system has a limited number of resources, a maximum recommended load, and some measure of flexibility in pushing beyond normal operating limits. You can overclock a computer if you need some extra processing power, and you can ask staff to add to their workload to pull through a busy period. But MDM implementation is a massive undertaking, and no system can overclock indefinitely without melting into slag.
- Crunching the numbers: Processing data takes time. On a single endpoint device, we don’t notice much anymore with how fast machines have gotten. But like the speed of light, it only seems instantaneous because of how close the finish line is. Once you scale things up, the lag becomes unmistakable. So, tasks like data scrubbing can be less like flipping a switch and more like running a production line, with all the delays, costs, and bandwidth reduction that comes with it.
- Adding to the family: M&A events are a nightmare for IT/I&O staff. Full stop. It’s a whole thing. But while master data can certainly ease some of the difficulties involved in folding a mountain of new data into the system all at once, it’s still a bunch of new data, none of which is standardized in the same ways as yours. Oh, and there are new stakeholders to potentially forestall reaching a consensus on what those standards should be.
MDM products and solutions
MDM providers aim to support I&O teams in either creating the master data record, maintaining said record once created, or both, typically through the use of specialized software tools.
Data scrubbing tools help you standardize and cleanse your data rather than having to remove duplicates and correct errors by hand. In some cases, the software can mediate data conflicts and updates without forcing you to rebuild your entire system architecture to facilitate it. There’s a lot of convenience and efficiency to benefit from with solutions in this product category, so feel free to start with these examples and expand your research from there.
PiLog MDRM
Marketed as a data governance suite, PiLog is more than just a master data record manager. Its MDM functionality is part of a larger tool set designed to help you establish complete control and oversight in your GRC efforts regarding data and digital privacy.
Informatica Master Data Management Platform
Informatica’s major value propositions are rooted in simplicity and ease of use. Designed to be deployed quickly, user-friendly, and with AI-powered implementation, Informatica is clearly going for push-button execution here. They do all the heavy lifting, making things easier both for the business and tech pros who normally have to do all the grunt work on stuff like this.
IBM InfoSphere Master Data Management
From the same brand that brought you all those totally radical business computing machines you see in all the 80s movies, InfoSphere leans heavily into IBM’s AI and predictive data solutions to highlight its potential value. We already know that data can be powerful, and if you need to get your data organized and cleaned up, why not put it to work for you while you’re at it? That’s IBM’s stance on it anyway.


